spatie/http-status-check
Stars: 585
Forks: 87
Pull Requests: 56
Issues: 31
Watchers: 20
Last Updated: 2023-06-14 13:16:35
CLI tool to crawl a website and check HTTP status codes
License: MIT License
Languages: PHP, JavaScript, Shell
Check the HTTP status code of all links on a website

![]()

This repository provides a tool to check the HTTP status code of every link on a given website.
Support us

We invest a lot of resources into creating best in class open source packages. You can support us by buying one of our paid products.
We highly appreciate you sending us a postcard from your hometown, mentioning which of our package(s) you are using. You'll find our address on our contact page. We publish all received postcards on our virtual postcard wall.
Installation
This package can be installed via Composer:
composer global require spatie/http-status-checkUsage
This tool will scan all links on a given website:
http-status-check scan https://example.comIt outputs a line per link found. Here's an example on Laracast website scan:
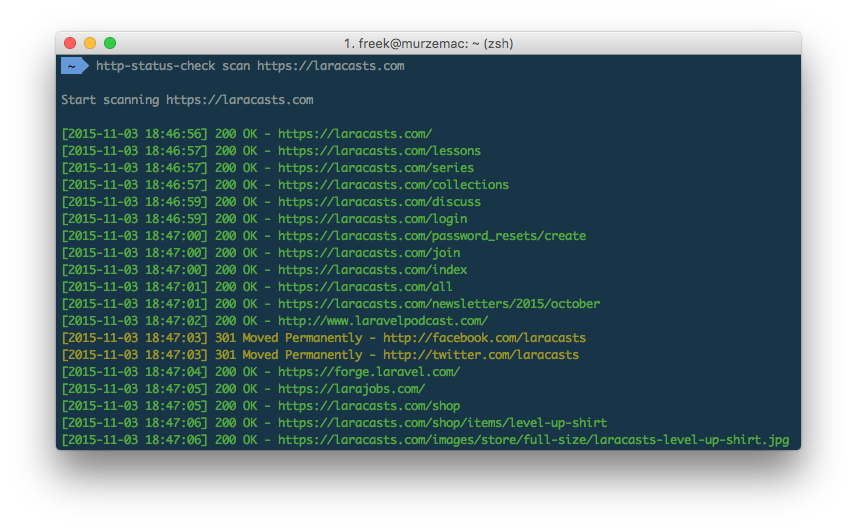
When the crawling process is finished a summary will be shown.
By default the crawler uses 10 concurrent connections to speed up the crawling process. You can change that number by passing a different value to the --concurrency option:
http-status-check scan https://example.com --concurrency=20You can also write all urls that gave a non-2xx or non-3xx response to a file:
http-status-check scan https://example.com --output=log.txtWhen the crawler finds a link to an external website it will by default crawl that link as well. If you don't want the crawler to crawl such external urls use the --dont-crawl-external-links option:
http-status-check scan https://example.com --dont-crawl-external-linksBy default, requests timeout after 10 seconds. You can change this by passing the number of seconds to the --timeout option:
http-status-check scan https://example.com --timeout=30By default, the crawler will respect robots data. You can ignore them though with the --ignore-robots option:
http-status-check scan https://example.com --ignore-robotsIf your site requires a basic authentification, you can use the --auth option:
http-status-check scan https://example.com --auth=username:passwordTesting
To run the tests, first make sure you have Node.js installed. Then start the included node based server in a separate terminal window:
cd tests/server
npm install
node server.jsWith the server running, you can start testing:
vendor/bin/phpunitChangelog
Please see CHANGELOG for more information on what has changed recently.
Contributing
Please see CONTRIBUTING for details.
Security
If you've found a bug regarding security please mail [email protected] instead of using the issue tracker.
Credits
License
The MIT License (MIT). Please see License File for more information.
RELEASES
See all- 0.0.1 by @freekmurze
- 1.0.0 by @freekmurze
- 1.0.1 by @freekmurze
- 1.0.2 by @freekmurze
- 2.0.0 by @freekmurze
- 2.1.0 by @freekmurze
- 2.1.1 by @freekmurze
- 2.2.0 by @freekmurze
- 2.2.1 by @freekmurze
- 2.3.0 by @freekmurze
- 2.4.0 by @freekmurze
- 2.5.0 by @freekmurze
- 3.0.0 by @freekmurze
- 3.1.0 by @freekmurze
- 3.1.1 by @brendt
- 3.1.2 by @freekmurze
- 3.1.3 by @freekmurze
- 3.1.4 by @freekmurze
- 3.2.0 by @freekmurze
- 3.3.0 by @freekmurze
- 3.4.0 by @freekmurze
- 4.0.0 by @freekmurze